.svg)
Blogs
What is Database Sharding and How Does It Work?
Enhancing Scalability and Performance in Modern Applications
Enhancing Scalability and Performance in Modern Applications
January 18, 2024
7 min read
.svg)
.svg)



Blogs
Enhancing Scalability and Performance in Modern Applications

Gaurav Kumar



In today's data-driven world, modern applications face the ever-growing challenge of managing massive volumes of information. Traditional monolithic databases struggle with bottlenecks, leading to sluggish performance and limited scalability. Enter database sharding—a powerful solution designed to enhance scalability and boost performance by distributing data across multiple shards.
Database sharding is a technique for horizontal scaling of databases, where the data is split across multiple database instances, or shards, to improve performance and reduce the impact of large amounts of data on a single database. (ref: Database Sharding)
Each shard is essentially a separate database instance or server that contains a subset of the overall data. The goal of sharding is to distribute the data and database load across multiple shards, allowing for improved scalability, performance, and fault tolerance in a distributed system.
Now that we have a foundational understanding of database sharding and its benefits, let's dive into a practical implementation example using Node.js and MongoDB.
In this example, we have created two database instances, both hosted on Atlas. You can also use Docker or self-host if you prefer.
To define the shard map, create a simple JavaScript object that maps product categories to their respective shard connection strings.
const shardMap = {
'Clothing': 'database url for clothing products',
'Electronics': 'database url for electronics products',
'default': 'database url for all other products'
}
Create a function that takes a product category as input and returns the appropriate shard connection.
// Fetch the right shard
const fetchShard = (category) => {
// get shard credentials
const credentials = shardMap?.[category]
// connect with the server
return new MongoClient(credentials ?? shardMap?.default);
}
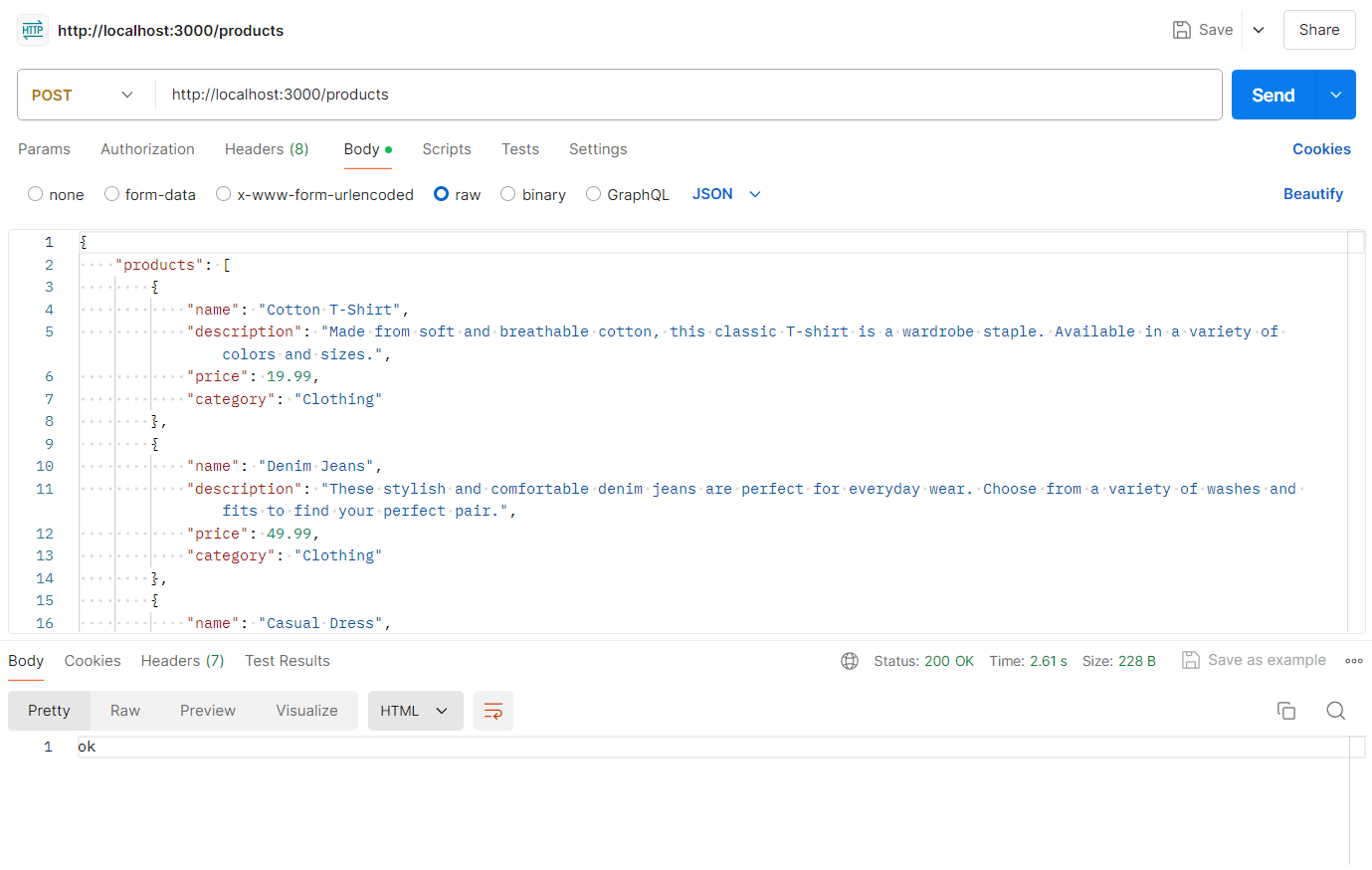
Set up an API route to handle product uploads. This route will use the fetchShard function to determine the correct shard for storing the product.
app.post('/products', async (req, res) => {
const {products} = req.body;
for (const product of products) {
// get database connection for each product
const client = await fetchShard(product?.category)
const db = client.db('database-sharding')
const productCollection = db.collection("products");
await productCollection.insertOne(product)
}
res.send("ok")
})
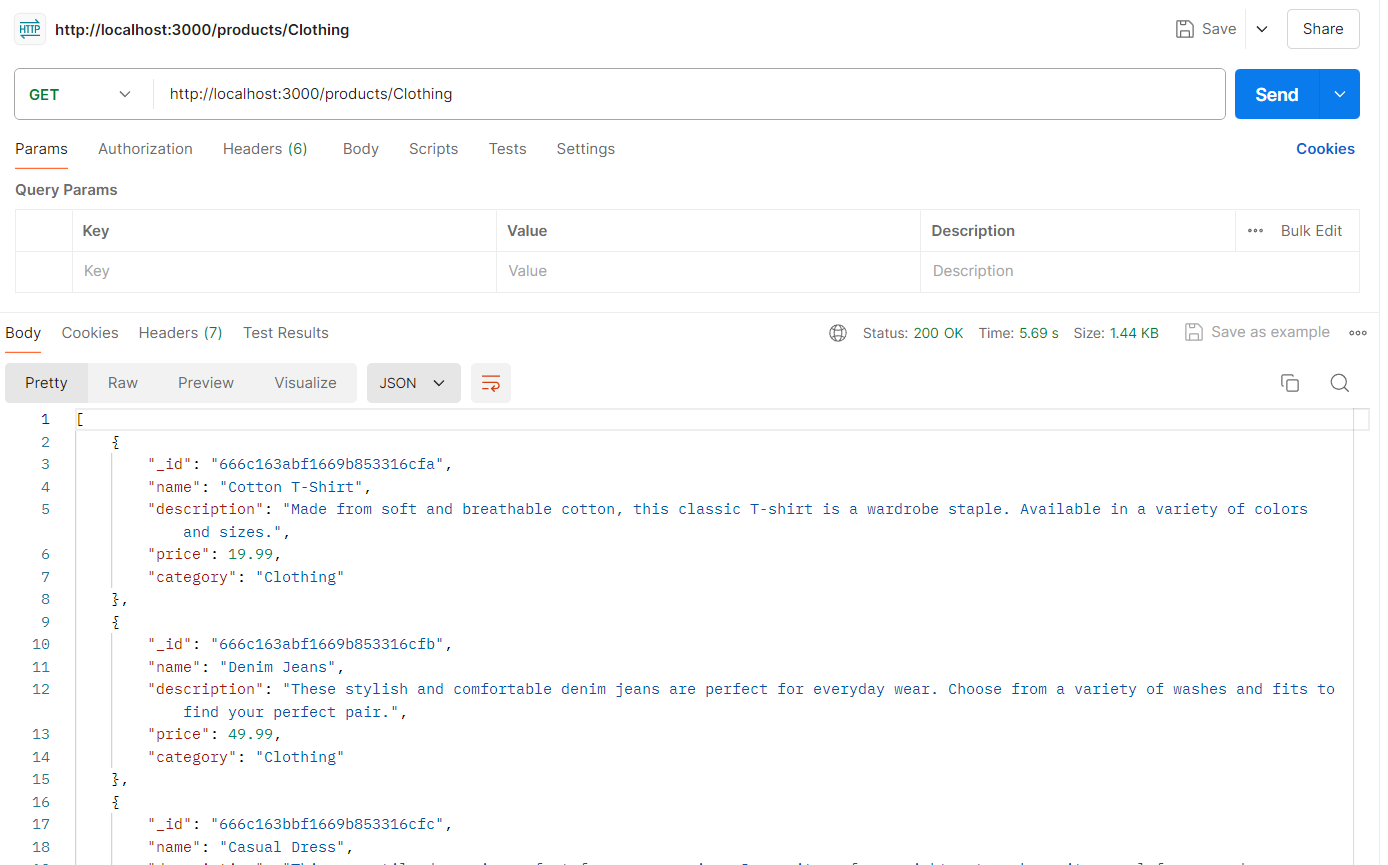
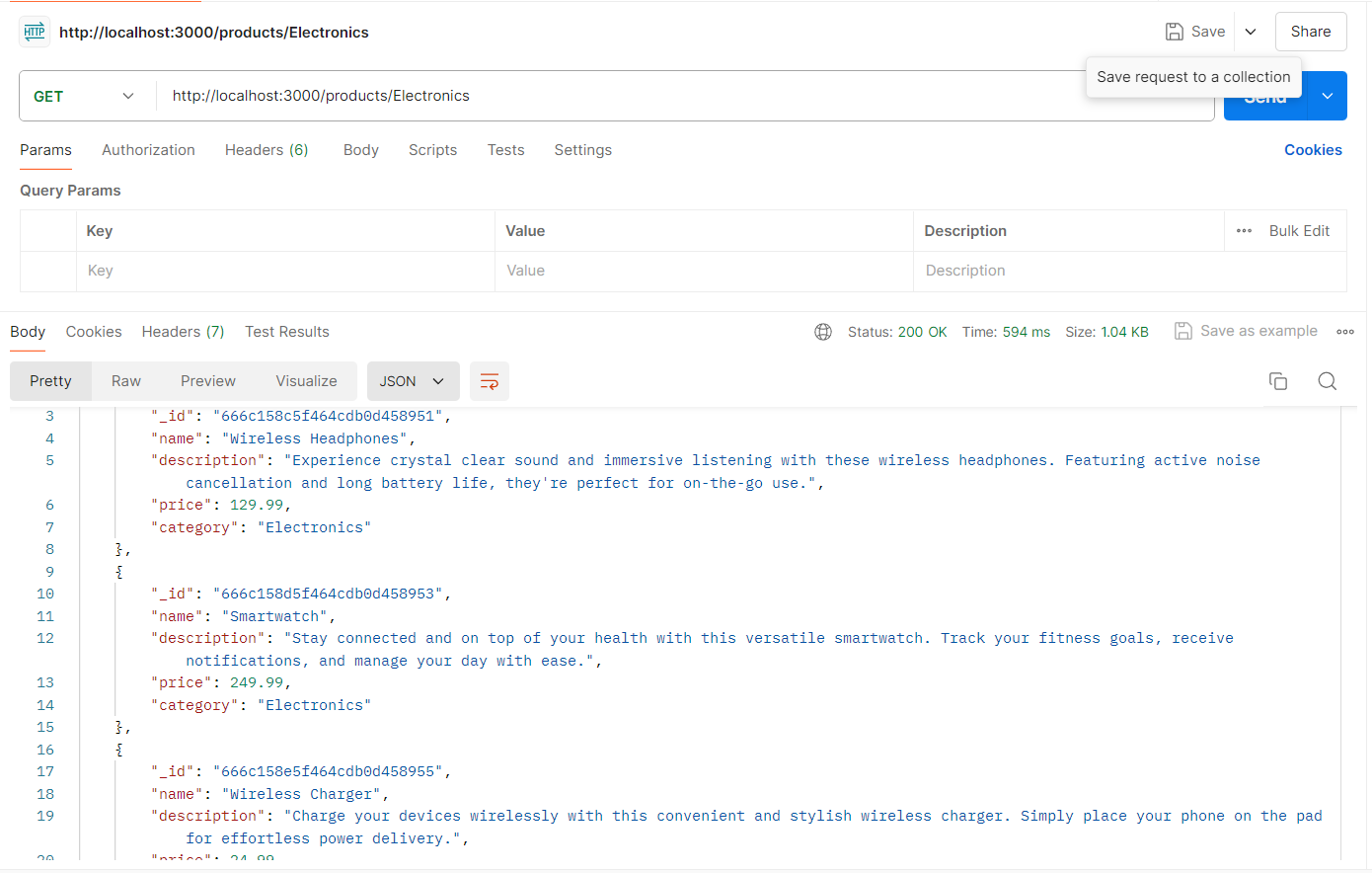
Set up an API route to fetch products by category. This route will also use the fetchShard function to determine the correct shard to query.
app.get('/products/:category', async (req, res) => {
const {category} = req.params;
try {
// find out the correct shard
const client = await fetchShard(category)
// connect to the database
const db = client.db('database-sharding')
const productCollection = db.collection("products");
const products = await productCollection.find({category}).toArray();
res.send(products)
} catch (err) {
console.log(err)
res.status(500).json({message: 'Error fetching products'});
}
});
To test the application, you can use tools like Postman or Curl to send HTTP requests to the API endpoints. For example:
Database sharding offers significant advantages in terms of scalability and performance, but it's important to be aware of its complexities and best practices for successful implementation:
By understanding the benefits and considerations of sharding, you can make informed decisions to optimize your Node.js applications for scalability and performance as your data demands continue to evolve. Remember, sharding is a powerful tool, but like any powerful tool, it requires careful planning and execution to reap the maximum rewards.

.svg)



.jpg)



.svg)
